1 .算力時代,GPU開拓新場景
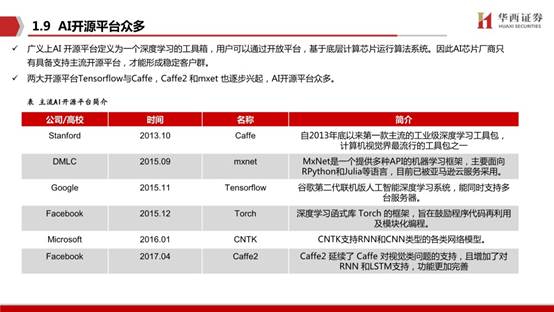
廣義上講只要能夠運行人工智能算法的芯片都叫作 AI 芯片。但是通常意義上的 AI 芯片指的是針對人工智能算法做了特殊加速設計的芯片。AI芯片也被稱為AI加速器或計算卡,即專門用于處理人工智能應用中的大量計算任務的模塊(其他非計算任務仍由CPU負責)。
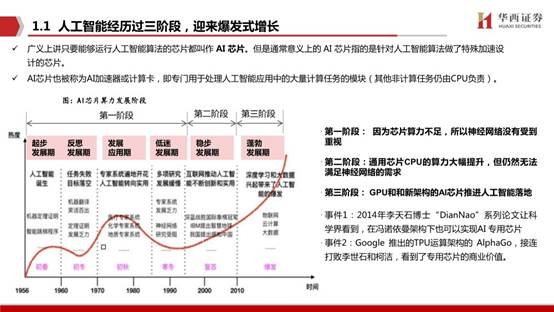
第一階段: 因為芯片算力不足,所以神經網絡沒有受到重視;
第二階段:通用芯片CPU的算力大幅提升,但仍然無法滿足神經網絡的需求;
第三階段: GPU和和新架構的AI芯片推進人工智能落地。
GPT-3模型目前已入選了《麻省理工科技評論》2021年“十大突破性技術。 GPT-3的模型使用的最大數據集在處理前容量達到了45TB。根據 OpenAI的算力統計單位petaflops/s-days,訓練AlphaGoZero需要1800-2000pfs-day,而GPT-3用了3640pfs-day。
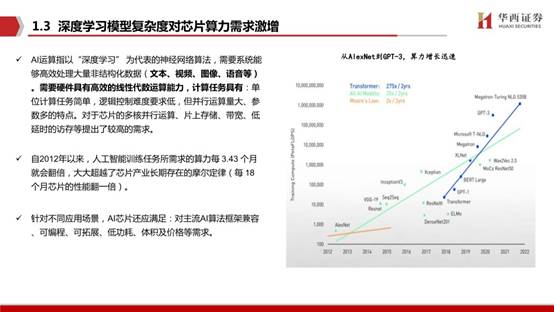
AI運算指以“深度學習” 為代表的神經網絡算法,需要系統能夠高效處理大量非結構化數據(文本、視頻、圖像、語音等)。需要硬件具有高效的線性代數運算能力,計算任務具有:單位計算任務簡單,邏輯控制難度要求低,但并行運算量大、參數多的特點。對于芯片的多核并行運算、片上存儲、帶寬、低延時的訪存等提出了較高的需求。
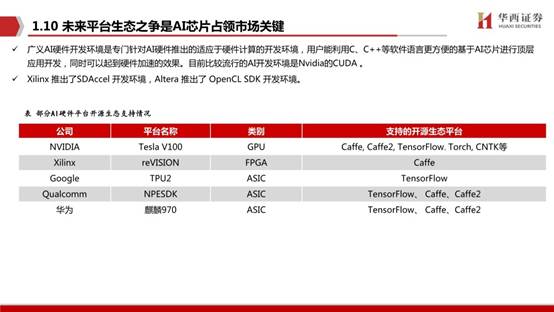
自2012年以來,人工智能訓練任務所需求的算力每 3.43個月就會翻倍,大大超越了芯片產業長期存在的摩爾定律(每 18個月芯片的性能翻一倍)。針對不同應用場景,AI芯片還應滿足:對主流AI算法框架兼容、可編程、可拓展、低功耗、體積及價格等需求。
根據機器學習算法步驟,可分為訓練(training)芯片和推斷(inference)芯片。訓練芯片主要是指通過大量的數據輸入,構建復雜的深度神經網絡模型的一種AI芯片,運算能力較強。推斷芯片主要是指利用訓練出來的模型加載數據,計算“推理”出各種結論的一種AI芯片,側重考慮單位能耗算力、時延、成本等性能。
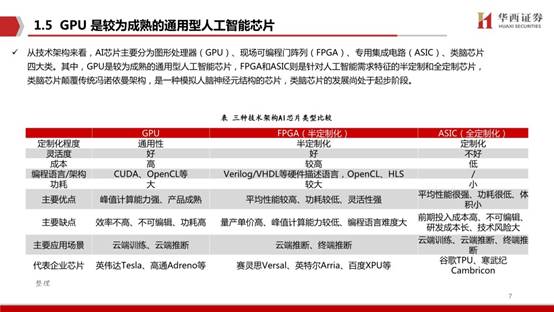
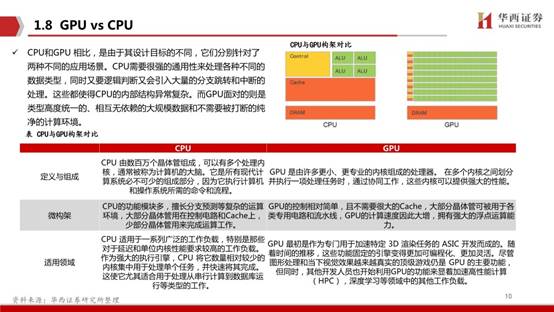
從技術架構來看,AI芯片主要分為圖形處理器(GPU)、現場可編程門陣列(FPGA)、專用集成電路(ASIC)、類腦芯片四大類。其中,GPU是較為成熟的通用型人工智能芯片,FPGA和ASIC則是針對人工智能需求特征的半定制和全定制芯片,類腦芯片顛覆傳統馮諾依曼架構,是一種模擬人腦神經元結構的芯片,類腦芯片的發展尚處于起步階段。
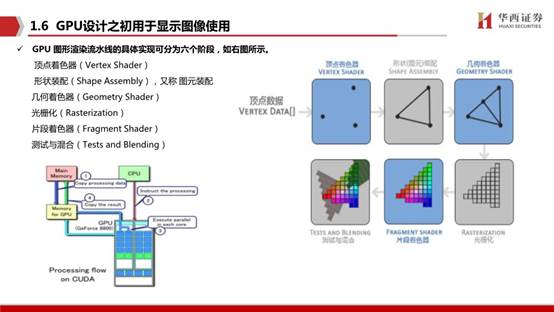
GPU(圖形處理器)又稱顯示核心、顯卡、視覺處理器、顯示芯片或繪圖芯片,是一種專門在個人電腦、工作站、游戲機和一些移動設備(如平板電腦、智能手機等)上運行繪圖運算工作的微處理器。GPU使顯卡減少對CPU的依賴,并分擔部分原本是由CPU所擔當的工作,尤其是在進行三維繪圖運算時,功效更加明顯。圖形處理器所采用的核心技術有硬件坐標轉換與光源、立體環境材質貼圖和頂點混合、紋理壓縮和凹凸映射貼圖、雙重紋理四像素256位渲染引擎等。GPU是一種特殊類型的處理器,具有數百或數千個內核,經過優化,可并行運行大量計算。雖然GPU在游戲中以3D渲染而聞名,但它們對運行分析、深度學習和機器學習算法尤其有用。
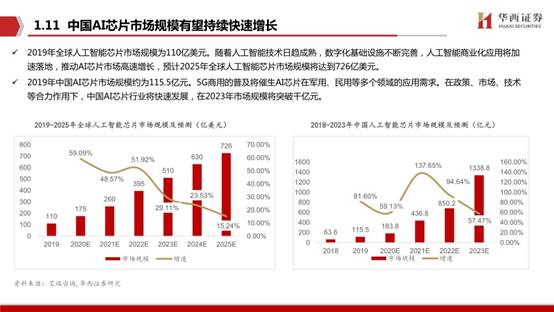
2019年全球人工智能芯片市場規模為110億美元。隨著人工智能技術日趨成熟,數字化基礎設施不斷完善,人工智能商業化應用將加速落地,推動AI芯片市場高速增長,預計2025年全球人工智能芯片市場規模將達到726億美元。2019年中國AI芯片市場規模約為115.5億元。5G商用的普及將催生AI芯片在軍用、民用等多個領域的應用需求。在政策、市場、技術等合力作用下,中國AI芯片行業將快速發展,在2023年市場規模將突破千億元。
2 .GPU 下游三大應用市場
GPU其實是由硬件實現的一組圖形函數的集合,這些函數主要用于繪制各種圖形所需要的運算。這些和像素,光影處理,3D坐標變換等相關的運算由GPU硬件加速來實現。圖形運算的特點是大量同類型數據的密集運算——如圖形數據的矩陣運算,GPU的微架構就是面向適合于矩陣類型的數值計算而設計的,大量重復設計的計算單元,這類計算可以分成眾多獨立的數值計算——大量數值運算的線程,而且數據之間沒有像程序執行的那種邏輯關聯性。
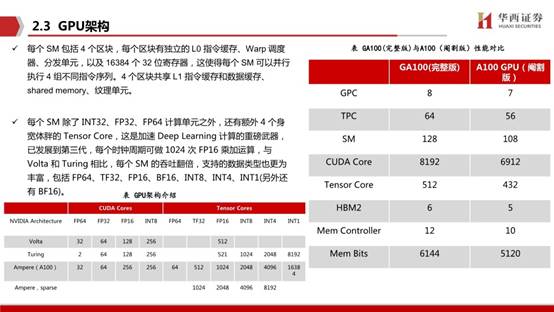
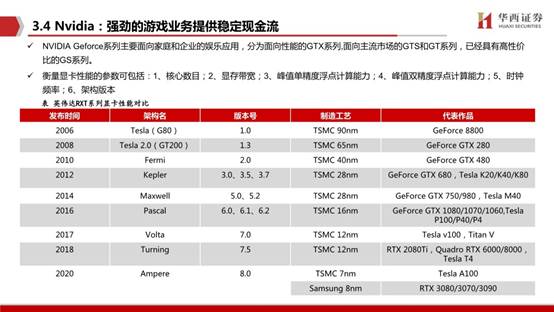
GPU微架構的設計研發是非常重要的,先進優秀的微架構對GPU實際性能的提升是至關重要的。目前市面上有非常豐富GPU微架構,比如Pascal、Volta、Turing(圖靈)、Ampere(安培),分別發布于 2016 年、2017 年、2018年和2020年,代表著英偉達 GPU 的最高工藝水平。
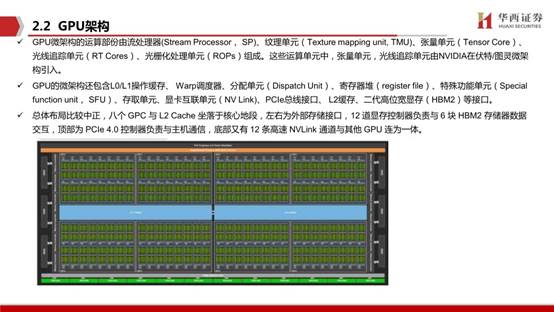
GPU微架構的運算部份由流處理器(Stream Processor, SP)、紋理單元(Texture mapping unit, TMU)、張量單元(Tensor Core)、光線追蹤單元(RT Cores)、光柵化處理單元(ROPs)組成。這些運算單元中,張量單元,光線追蹤單元由NVIDIA在伏特/圖靈微架構引入。GPU的微架構還包含L0/L1操作緩存、 Warp調度器、分配單元(Dispatch Unit)、寄存器堆(register file)、特殊功能單元(Specialfunction unit, SFU)、存取單元、顯卡互聯單元(NV Link)、PCIe總線接口、 L2緩存、二代高位寬顯存(HBM2)等接口。
總體布局比較中正,八個 GPC 與 L2 Cache 坐落于核心地段,左右為外部存儲接口,12 道顯存控制器負責與 6 塊 HBM2 存儲器數據交互,頂部為 PCIe 4.0 控制器負責與主機通信,底部又有 12 條高速 NVLink 通道與其他 GPU 連為一體。
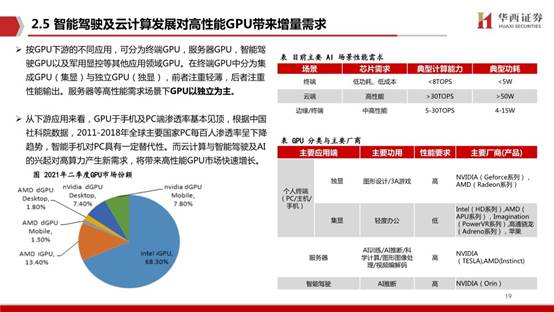
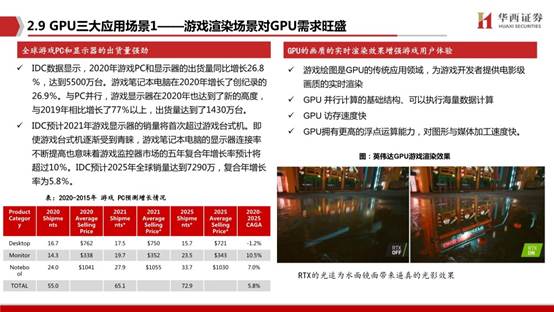
按GPU下游的不同應用,可分為終端GPU,服務器GPU,智能駕駛GPU以及軍用顯控等其他應用領域GPU。在終端GPU中分為集成GPU(集顯)與獨立GPU(獨顯),前者注重輕薄,后者注重性能輸出。服務器等高性能需求場景下GPU以獨立為主。
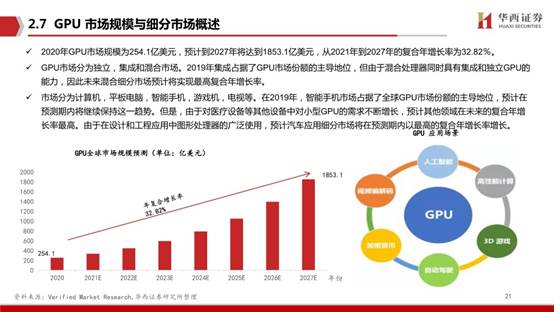
2020年GPU市場規模為254.1億美元,預計到2027年將達到1853.1億美元,從2021年到2027年的復合年增長率為32.82%。GPU市場分為獨立,集成和混合市場。2019年集成占據了GPU市場份額的主導地位,但由于混合處理器同時具有集成和獨立GPU的能力,因此未來混合細分市場預計將實現最高復合年增長率。
市場分為計算機,平板電腦,智能手機,游戲機,電視等。在2019年,智能手機市場占據了全球GPU市場份額的主導地位,預計在預測期內將繼續保持這一趨勢。但是,由于對醫療設備等其他設備中對小型GPU的需求不斷增長,預計其他領域在未來的復合年增長率最高。由于在設計和工程應用中圖形處理器的廣泛使用,預計汽車應用細分市場將在預測期內以最高的復合年增長率增長。
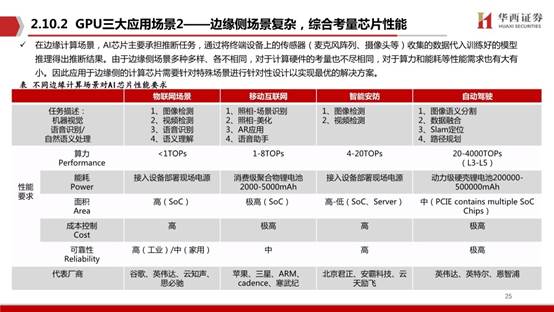
在邊緣計算場景,AI芯片主要承擔推斷任務,通過將終端設備上的傳感器(麥克風陣列、攝像頭等)收集的數據代入訓練好的模型推理得出推斷結果。由于邊緣側場景多種多樣、各不相同,對于計算硬件的考量也不盡相同,對于算力和能耗等性能需求也有大有小。因此應用于邊緣側的計算芯片需要針對特殊場景進行針對性設計以實現最優的解決方案。
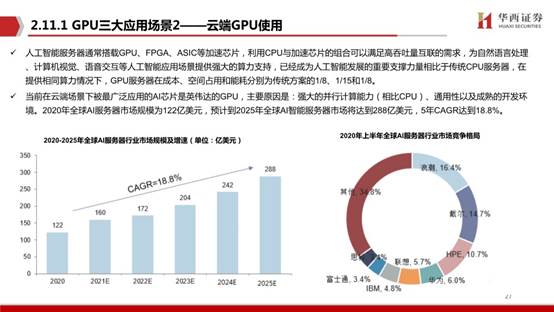
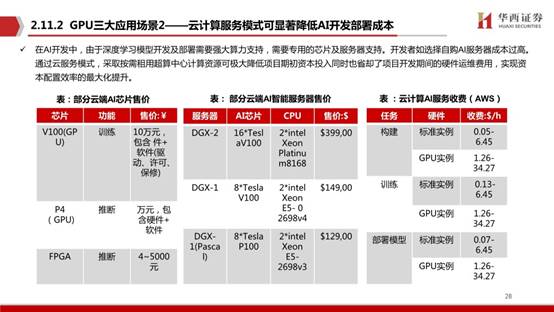
人工智能服務器通常搭載GPU、FPGA、ASIC等加速芯片,利用CPU與加速芯片的組合可以滿足高吞吐量互聯的需求,為自然語言處理、計算機視覺、語音交互等人工智能應用場景提供強大的算力支持,已經成為人工智能發展的重要支撐力量相比于傳統CPU服務器,在提供相同算力情況下,GPU服務器在成本、空間占用和能耗分別為傳統方案的1/8、1/15和1/8。
當前在云端場景下被最廣泛應用的AI芯片是英偉達的GPU,主要原因是:強大的并行計算能力(相比CPU)、通用性以及成熟的開發環境。2020年全球AI服務器市場規模為122億美元,預計到2025年全球AI智能服務器市場將達到288億美元,5年CAGR達到18.8%。
3 .海外GPU巨頭Nvidia
GPU通用計算方面的標準目前有OpenCL、CUDA、AMD APP、DirectCompute。其中OpenCL、DirectCompute、AMD APP(基于開放型標準OpenCL開發)是開放標準,CUDA是私有標準。(報告來源:未來智庫)
2006年,公司推出CUDA 軟件推展,推動GPU 向通用計算轉變,之后不斷強化通用系統生態構建。為開發者提供了豐富的開發軟件站SDK、支持現有的大部分機器學習、深度學習開發框架。推出的cuDNN、TensorRT、DeepStream 等優化的軟件也為 GPU 通用計算提供加速 。
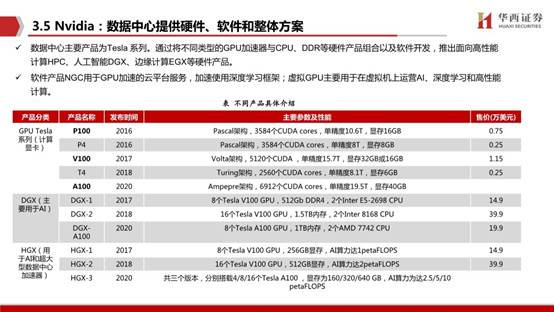
NVIDIA Geforce系列主要面向家庭和企業的娛樂應用,分為面向性能的GTX系列,面向主流市場的GTS和GT系列,已經具有高性價比的GS系列。數據中心主要產品為Tesla 系列。通過將不同類型的GPU加速器與CPU、DDR等硬件產品組合以及軟件開發,推出面向高性能計算HPC、人工智能DGX、邊緣計算EGX等硬件產品。軟件產品NGC用于GPU加速的云平臺服務,加速使用深度學習框架;虛擬GPU主要用于在虛擬機上運營AI、深度學習和高性能計算。
融合了Mellanox 的計算推了DPU的產品。BlueField DPU 通過分流、加速和隔離各種高級網絡、存儲和安全服務,為云、數據中心或邊緣等環境中的各種工作負載提供安全的加速基礎設施。BlueField DPU 將計算能力、數據中心基礎功能的可編程性及高性能網絡相結合,可實現非常高的工作負載。
GPC 2021年推出了基于ARM 架構的面向服務器市場的CPU,用于大型計算中心或者超級計算機等場景中,通過Nvlink 實現CPU、GPU 之間的大帶寬鏈接和交互。未來數據中心將具備 GPU+CPU+DPU 整體解決方案。
4 .國產GPU賽道掀起投資熱潮
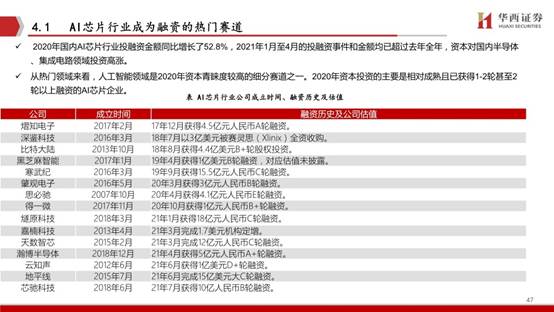
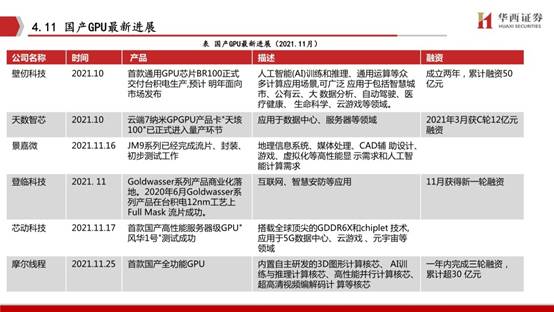
2020年國內AI芯片行業投融資金額同比增長了52.8%,2021年1月至4月的投融資事件和金額均已超過去年全年,資本對國內半導體、集成電路領域投資高漲。
從熱門領域來看,人工智能領域是2020年資本青睞度較高的細分賽道之一。2020年資本投資的主要是相對成熟且已獲得1-2輪甚至2輪以上融資的AI芯片企業。沐曦集成電路專注于設計具有完全自主知識產權,針對異構計算等各類應用的高性能通用GPU芯片。
公司致力于打造國內最強商用GPU芯片,產品主要應用方向包含傳統GPU及移動應用,人工智能、云計算、數據中心等高性能異構計算領域,是今后面向社會各個方面通用信息產業提升算力水平的重要基礎產品。
擬采用業界最先進的5nm工藝技術,專注研發全兼容CUDA及ROCm生態的國產高性能GPU芯片,滿足HPC、數據中心及AI等方面的計算需求。致力于研發生產擁有自主知識產權的、安全可靠的高性能GPU芯片,服務數據中心、云游戲、人工智能等需要高算力的諸多重要領域。
壁仞科技創立于2019年,公司在GPU和DSA(專用加速器)等領域具備豐富的技術儲備聚焦于云端通用智能計算,逐步在AI訓練和推理、圖形渲染、高性能通用計算等多個領域趕超現有解決方案,以實現國產高端通用智能計算芯片的突破。
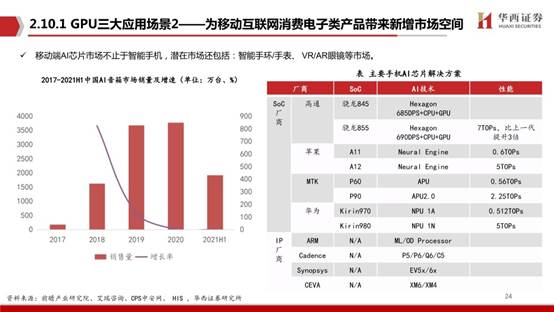
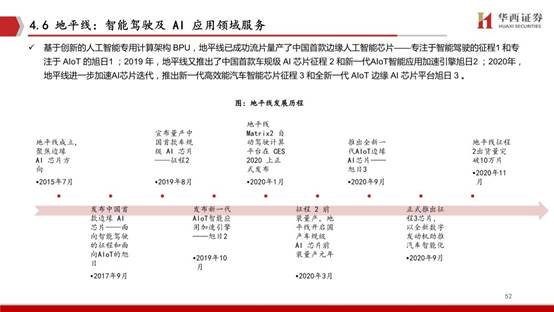
智能物聯網需求將使云端計算的負荷成倍增長。智能物聯網是未來的趨勢所向,海量的碎片化場景與計算旭日處理器強大的邊緣計算能力,幫助設備高效處理本地數據。面向AIoT,地平線推出旭日系列邊緣 AI 芯片。旭日2采用 BPU 伯努利1.0 架構,可提供 4TOPS 等效算力,旭日3 采用伯努利2.0 ,可提供 5TOPS 的等效算力。
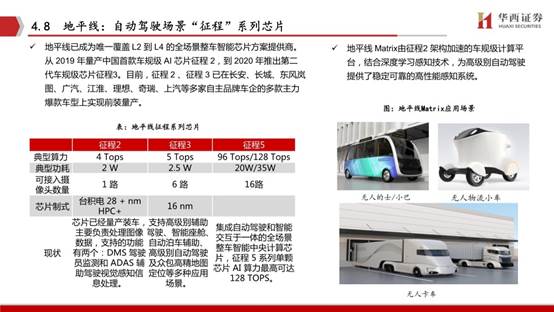
黑芝麻智能科技是一家專注于視覺感知技術與自主IP芯片開發的企業。公司主攻領域為嵌入式圖像和計算機視覺,提供基于光控技術、圖像處理、計算圖像以及人工智能的嵌入式視覺感知芯片計算平臺,為ADAS及自動駕駛提供完整的商業落地方案。
基于華山二號 A1000 芯片,黑芝麻提供了四種智能駕駛解決方案。單顆 A1000L 芯片適用于 ADAS 輔助駕駛;單顆 A1000 芯片適用于 L2+ 自動駕駛;雙 A1000 芯片互聯可達 140TOPS 算力,支持 L3 等級自動駕駛;四顆 A1000 芯片則可以支持 L4 甚至以上的自動駕駛需求。另外,黑芝麻還可以根據不同的客戶需求,提供定制化服務。
黑芝麻智能首款芯片與上汽的合作已實現量產,第二款芯片A1000正在量產過程中,預計今年下半年在商用車領域實現10萬片量級以上的量產,明年將在乘用車領域量產落地。黑芝麻智能已與一汽、蔚來、上汽、比亞迪、博世、滴滴、中科創達、亞太機電等企業在L2、L3級自動駕駛感知系統解決方案上均有合作。
5 .重點公司分析
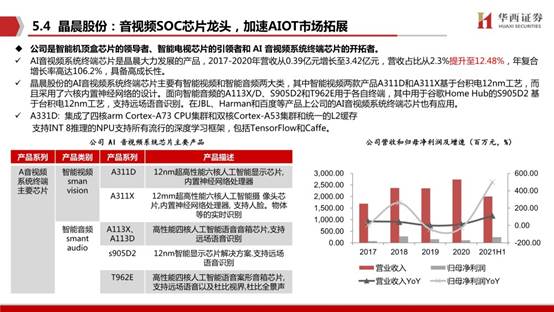
晶晨股份:公司是智能機頂盒芯片的領導者、智能電視芯片的引領者和 AI 音視頻系統終端芯片的開拓者。AI音視頻系統終端芯片是晶晨大力發展的產品,2017-2020年營收從0.39億元增長至3.42億元,營收占比從2.3%提升至12.48%,年復合增長率高達106.2%,具備高成長性。
晶晨股份的AI音視頻系統終端芯片主要有智能視頻和智能音頻兩大類,其中智能視頻兩款產品A311D和A311X基于臺積電12nm工藝,而且采用了六核內置神經網絡的設計。面向智能音頻的A113X/D、S905D2和T962E用于各自終端,其中用于谷歌Home Hub的S905D2 基于臺積電12nm工藝,支持遠場語音識別。在JBL、Harman和百度等產品上公司的AI音視頻系統終端芯片也有應用。
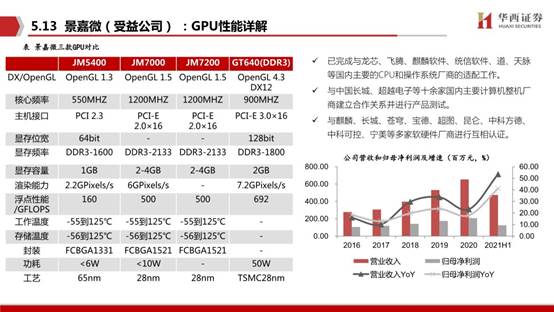
報告節選:































 京公網安備 11010802036102號北京金支點技術服務有限公司保留所有權利 | Copyright ? 2005-2025 Beijing Golden Point Outsourcing Service Co., Ltd. All Rights Reserved.
京公網安備 11010802036102號北京金支點技術服務有限公司保留所有權利 | Copyright ? 2005-2025 Beijing Golden Point Outsourcing Service Co., Ltd. All Rights Reserved.